
Останні дослідження в галузі штучного інтелекту презентували новий підхід до масштабування моделей, який, за словами його авторів, здатен суттєво покращити продуктивність ШІ. Однак, попри гучні заяви, багато експертів залишаються скептичними щодо його реальної ефективності.
Про метод та причини скепсису з боку фахівців розповіло видання TechCrunch.
Що таке закони масштабування ШІ та чому вони важливі?
Поняття масштабування ШІ описує, як покращується робота моделей у міру збільшення навчальних даних та обчислювальних потужностей. Традиційно основним методом було масштабування переднавчання, яке передбачало створення дедалі більших мовних моделей із доступом до значного обсягу інформації.
Втім, за останній рік з’явилися нові стратегії:
- Масштабування пост-навчання – коригування поведінки моделі після її основного навчального процесу.
- Масштабування на етапі виконання – використання додаткових обчислень під час роботи моделі для покращення її логічних навичок.
Нещодавно дослідники з Google та Каліфорнійського університету в Берклі запропонували ще один підхід – пошук на етапі виконання (inference-time search), який деякі аналітики вже називають четвертим законом масштабування.
Як працює новий метод пошуку?
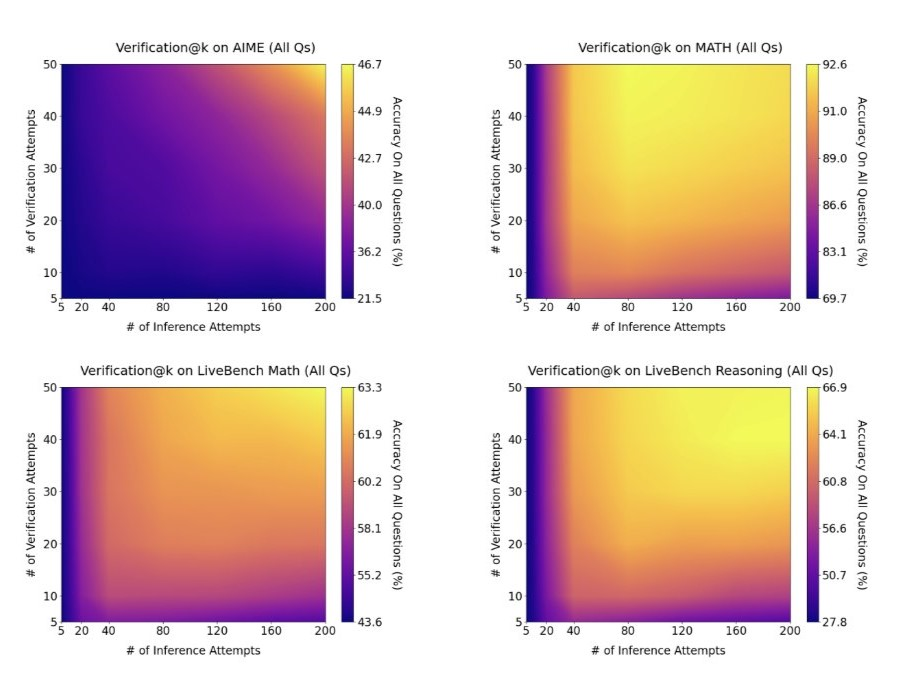
Згідно з концепцією, ШІ-модель генерує безліч варіантів відповіді та самостійно обирає найкращий. Це дозволяє навіть відносно старим моделям демонструвати вищу ефективність.
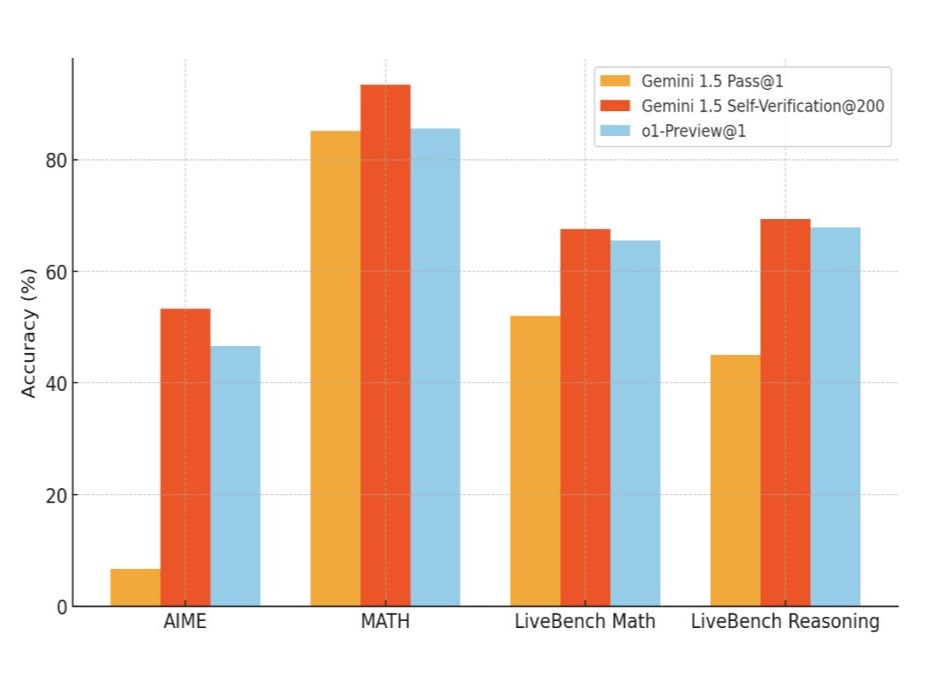
За словами розробників, Google Gemini 1.5 Pro, використовуючи цей підхід, перевершив OpenAI o1-preview у тестах з математики та природничих наук.
“Просто вибравши 200 випадкових відповідей і самостійно їх перевіривши, Gemini 1.5 – “стародавня” модель початку 2024 року – змогла обійти o1-preview та наблизитися до o1“, – зазначив у соцмережі X докторський стипендіат Google Ерік Чжао.
Він також додав, що збільшення масштабів моделі лише покращує ефективність самоперевірки, хоча інтуїтивно могло б здаватися навпаки.
Чому експерти скептичні?
Попри перспективи нового підходу, частина дослідників вважає, що метод пошуку на етапі виконання має суттєві обмеження.
Меттью Гуздіал, доцент Університету Альберти, пояснює, що метод працює лише там, де можна чітко визначити правильну відповідь.
«Якщо ми не можемо встановити точні критерії для правильної відповіді, то пошук на етапі виконання марний. Для звичайної взаємодії з мовною моделлю він не спрацює», – наголосив Гуздіал.
Його думку підтримує Майк Кук, науковий співробітник Королівського коледжу Лондона. За його словами, цей метод не покращує логічне мислення моделі, а лише допомагає компенсувати її слабкі сторони.
«Пошук на етапі виконання не робить ШІ “розумнішим”. Це всього лише спосіб зменшити ймовірність помилок, адже якщо модель помиляється у 5% випадків, перевіривши 200 варіантів, вона зможе швидше виявити свої неточності», – пояснив Кук.
Чи стане цей метод проривом?
Попри певні недоліки, ШІ-індустрія продовжує пошуки оптимальних методів масштабування, які б мінімізували витрати обчислювальних ресурсів.
Сучасні моделі, орієнтовані на логічний аналіз, можуть витрачати тисячі доларів на вирішення однієї задачі. Відтак, дослідники намагаються знайти ефективніші підходи до оптимізації ШІ.
Чи стане пошук на етапі виконання стандартом у цій сфері – питання відкрите. Але поки що індустрія продовжує експериментувати у пошуках нових рішень.